r에서 한글문서 열때 인코딩 문제
결론부터
R 공부를 시작하고 나서 한글이 들어있는 자료를 분석할 때, 가장 많이 보게되는 에러가 바로 아래와 인코딩 에러입니다.
read.csv("http://philogrammer.com/melon10_euc.csv")
## Error in make.names(col.names, unique = TRUE): '<bc><f8><c0><a7>'에서 유효하지 않은 멀티바이트 문자열이 있습니다
이것은 바로 R이 설치된 시스템의 인코딩과 실제 우리가 불러들이려는 파일의 인코딩이 맞지 않기 때문에 발생하는 문제입니다.
우리 팀에서 이런 문제가 발생하여 후배들이 많은 고생을 해서 ㅠㅠ 인코딩 에러를 피하기 위하여 read.any 라는 함수를 만들어 보았습니다.
함수를 붙여 넣기 귀찮으신 분들을 위하여 아주 단순한 코드이지만, 패키지화 하여 github에 올려놓았습니다. 아래와 같이 하시면 받으실 수 있습니다.
# Devtools 패키지를 설치합니다.
library(devtools)
# 패키지를 로드합니다.
install_github("plgrmr/readAny", force = TRUE)
library(readAny)
# 사용법은 read.table 과 100% 똑같습니다.
read.any("http://philogrammer.com/melon10_euc.csv", header = TRUE)
## 순위 가수
## 1 1 헤이즈 (Heize)
## 2 2 찬열 (CHANYEOL), 펀치 (Punch)
## 3 3 정승환
## 4 4 마마무
## 5 5 TWICE (트와이스)
## 6 6 지코 (ZICO)
## 7 7 김희철X민경훈
## 8 8 BLACKPINK
## 9 9 세정 (구구단)
## 10 10 볼빨간사춘기
## 노래제목
## 1 저 별
## 2 Stay With Me
## 3 이 바보야
## 4 Decalcomanie (데칼코마니)
## 5 TT
## 6 BERMUDA TRIANGLE (Feat. Crush, DEAN)
## 7 나비잠 (Sweet Dream)
## 8 불장난
## 9 꽃길 (Prod. By ZICO)
## 10 우주를 줄게
## 앨범 좋아요
## 1 저 별 60,236
## 2 도깨비 OST Part.1 50,776
## 3 목소리 55,467
## 4 MEMORY 57,929
## 5 TWICEcoaster : LANE 1 122,007
## 6 BERMUDA TRIANGLE 56,163
## 7 나비잠 (Sweet Dream) 73,895
## 8 SQUARE TWO 61,840
## 9 Jelly box 꽃길 (Prod. By 지코(ZICO)) 세정 60,647
## 10 Full Album RED PLANET 155,328
물론 아래 코드를 복사하여 붙여넣기 해서 함수를 생성해서 사용하셔도 무방합니다 :)
library(readr)
read.any <- function(text, sep = "", ...) {
encoding <- as.character(guess_encoding(text)[1,1])
setting <- as.character(tools::file_ext(text))
if(sep != "" | !(setting %in% c("csv", "txt")) ) setting <- "custom"
separate <- list(csv = ",", txt = "\n", custom = sep)
result <- read.table(text, sep = separate[[setting]], fileEncoding = encoding, ...)
return(result)
}
무엇이 문제인가?
 R 은 물론이고 Python 이나 SQL 등 다른 여러 언어 등을 시작할 때 가장 먼저 겪게 되는 문제가 바로 인코딩 문제입니다.
R 은 물론이고 Python 이나 SQL 등 다른 여러 언어 등을 시작할 때 가장 먼저 겪게 되는 문제가 바로 인코딩 문제입니다.

excel로 분석에 필요한 데이터를 정리해서 csv로 만든 다음 r에 읽어들였으나 열고나니 외계어가 나오고 영어는 잘 나오는데 한글은 꼬여서 나오기도 하고 이런 경우가 참 많이 있습니다.
사실 경험이 있는 분들에게는 대수로운 것이 아니지만 처음 시작하는 사람 입장에서는 곤욕스럽습니다.

특히 Windows 환경에서 작업하는 작업자와 Mac 상에서 작업하는 작업자 간 csv 로 자료를 교환할 때에 이런 이슈가 자주 발생하곤 합니다.
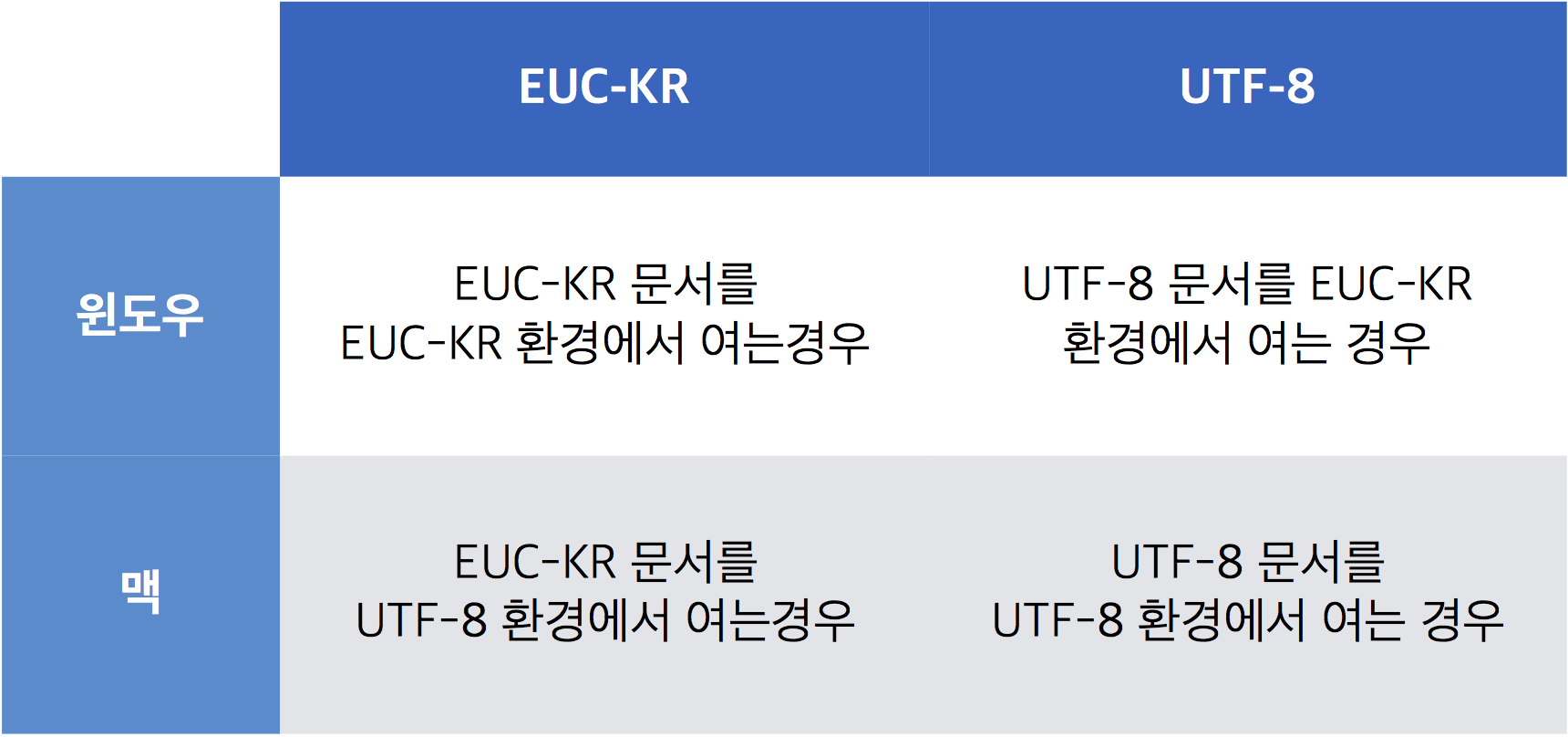
Mac 에서 작업하여 Export 한 csv 문서는 일반적으로 “UTF-8” 이라고 하는 유니코드 형태로 저장이 됩니다. 반면 Windows 환경에서 Export 된 csv 문서는 “EUC-KR” 인코딩으로 저장이 됩니다.
guess_encoding("http://philogrammer.com/melon10_euc.csv")
## encoding confidence
## 1 EUC-KR 1.00
## 2 GB18030 0.61
## 3 Big5 0.41
다른 경우의 수도 있는데요 제가 만들어본 함수에서는 다양한 상황에서 대처 할 수 있도록 문서의 encoding 을 자동으로 추측해서 파일을 읽을 때 지정될 수 있도록 하였습니다. guess_encoding 함수는 “readr” 패키지를 활용하였습니다.
as.character(tools::file_ext("http://philogrammer.com/melon10_euc.csv"))
## [1] "csv"
더불어 “,”” 로 분리되어 만들어진 csv 파일과 장문의 txt 파일같은 경우에는 따로 설정하지 않더라도 파일만 넣으면 확장자에 따라 자동으로 구분점을 설정하여 파일을 읽을 수 있게 만들어 놓아 편의를 도왔습니다.
살펴봅시다
library(readr)
read.any <- function(text, sep = "", ...) {
# readr 패키지에 있는 guess_encoding 함수를 사용하여
# 문서의 인코딩을 추측합니다.
# 다른 언어와 달리 한글과 같은 경우는 높은 확률로
# 인코딩을 찾아주어 실사용에 큰 무리가 없습니다.
encoding <- as.character(guess_encoding(text)[1,1])
# 파일 확장자에 따라 구분점을 다르게 처리해주는 부분입니다.
# 함수에 임의의 인자를 지정해 주는 경우를 제외하고는
# csv 파일인 경우 "," 를 구분점으로 설정하고
# txt 파일인 경우 "\n" 즉 개행문자를 구분점으로 설정하였습니다.
# csv 확장자와 txt 파일인 경우의 대응을 위해 확장자를 setting 변수에 저장해줍니다.
setting <- as.character(tools::file_ext(text))
# 임의의 sep 인자를 지정한 경우 혹은 csv나 txt 이외의 확장자를 가진 파일의 경우
# read.table 함수로 임의의 인자를 넘겨 줄 수 있도록 설정유형을 custom 이라고 해줍니다.
if(sep != "" | !(setting %in% c("csv", "txt")) ) setting <- "custom"
# csv 인 경우 구분자를 , 쉼표 txt 파일인 경우 \n 개행문자로 세팅합니다.
# \t 탭 등의 임의의 구분자 지정 시에는 임의의 구분자를 그대로 전달합니다.
separate <- list(csv = ",", txt = "\n", custom = sep)
# 결과 값을 전달해줍니다.
result <- read.table(text, sep = separate[[setting]], fileEncoding = encoding, ...)
return(result)
}